


去年3月底的时候小麦子来到了我家,到今天已经1岁1个月多了,现在这个小家伙已经能熟练快速爬,也能扶墙走几步了。
前天,小麦子一个人睡觉,大人们都在忙事情,结果这家伙自己醒了并且悄悄摸摸爬起来,结果不小心摔下了床。
于是我在思考,是否可以利用相关的识别技术来帮助自动监控小麦子睡觉情况呢?现在有大量成熟的案例,虽然不是搞python的,但是相信应该也问题不大,毕竟网上相关的教程和例子太多了。
需求
希望利用家里的老旧手机作为无线监控设备,能够自动识别小麦子睡醒状态并发出报警响铃。
技术方案设计
前端由于不熟悉Android和iOS的开发,并且从跨平台考虑,希望能够通过H5来实现。 基于H5,通信协议选择了音视频实时性相对较高的webRTC协议。WebRTC名称源自网页即时通信(英语:Web Real-Time Communication)的缩写,是一个支持网页浏览器进行实时语音对话或视频对话的API。
后端选择python,提供Https服务并且处理webRTC相关信令和流数据。具体使用了一个第三方库aiohttp和aiortc来提供服务。最后也是最核心的部分就是姿势和运动识别。实现
1.准备工作
- 环境
我使用的是MacBook Pro (13-inch, M1, 2020),提前安装了python版本3.8.9,pip安装了依赖库opencv-python 4.5.5.64、aiohttp 3.8.1、aiortc 1.3.1、av 9.1.1等。
- 自签名https证书 由于chrome安全限制使用webRTC时需通过https协议,所以我们提前生成自签名证书,参考下面的脚本
# 生成 key
openssl genrsa -des3 -out server.key 1024
# 生成 csr
openssl req -new -key server.key -out server.csr
# 去除密码
openssl rsa -in server.key -out server_nopass.key
# 生成证书
openssl x509 -req -days 365 -in server.csr -signkey server_nopass.key -out server.crt
2.代码
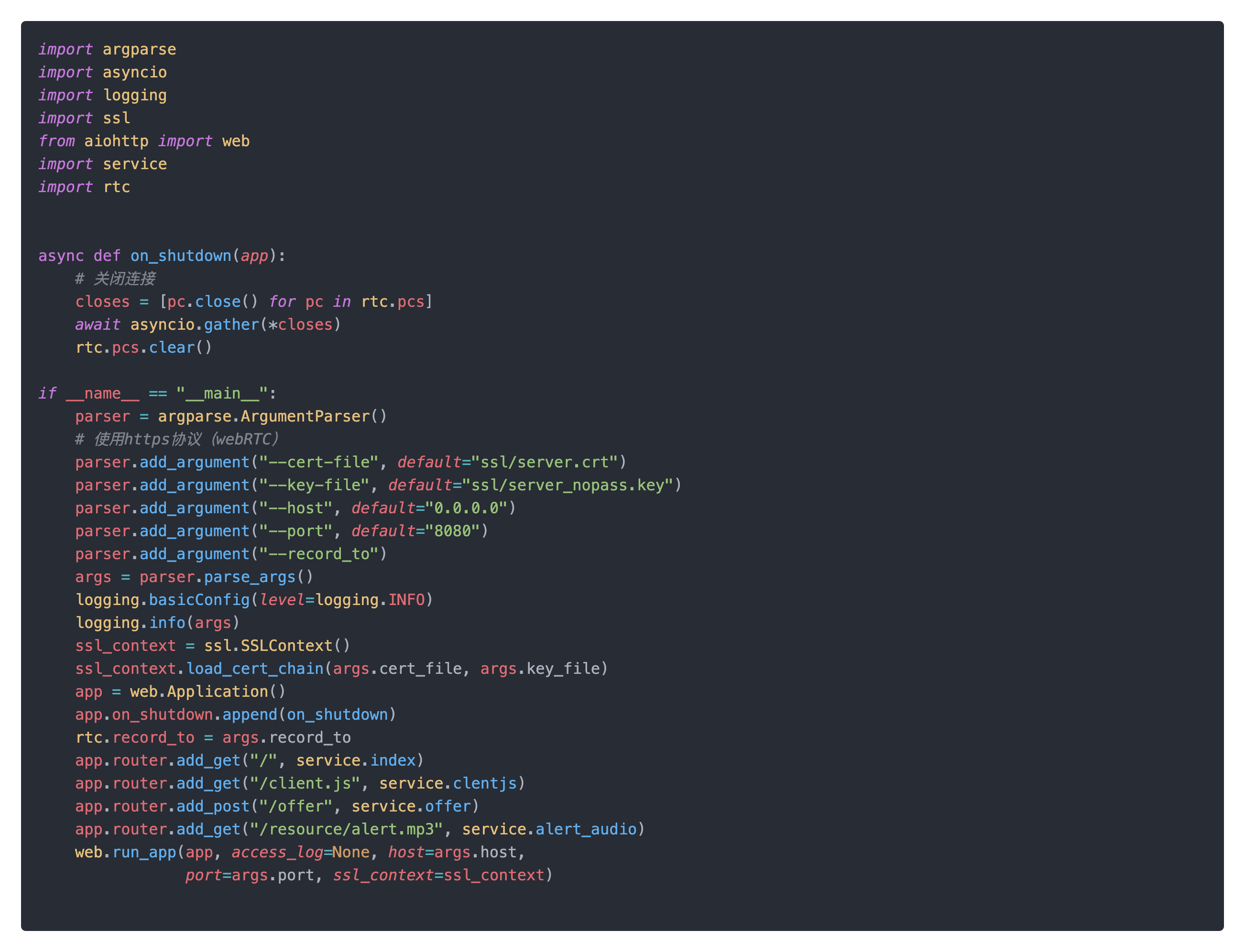
启动类bootstrap.py主要获取启动参数并启动一个https服务。可以手动指定启动ip和端口,也可以指定ssl相关参数。最后路由相关http请求到service.py
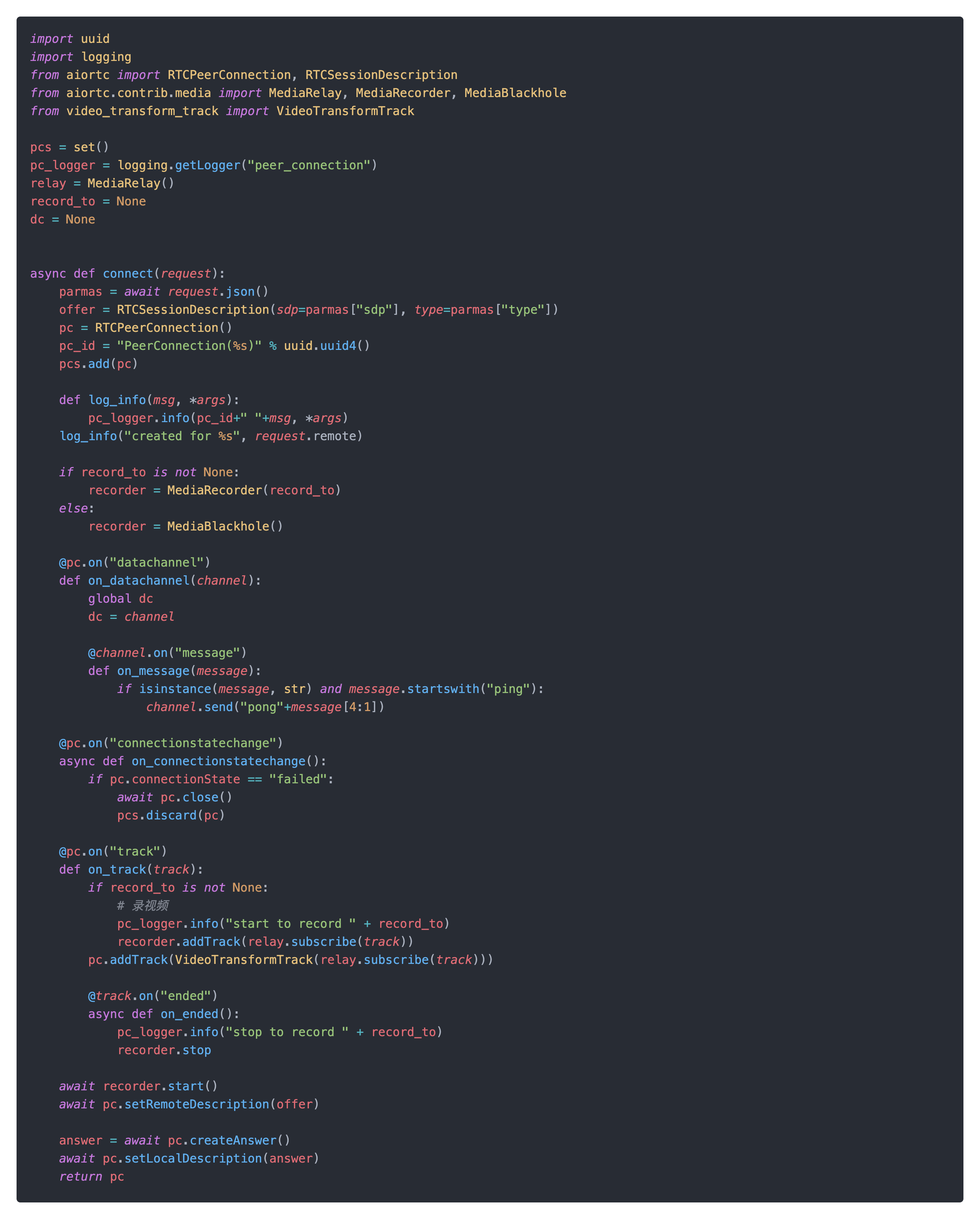
service.py主要处理相关request请求,其中offer主要处理webRTC的握手协议sdp信息并建立rtc连接。

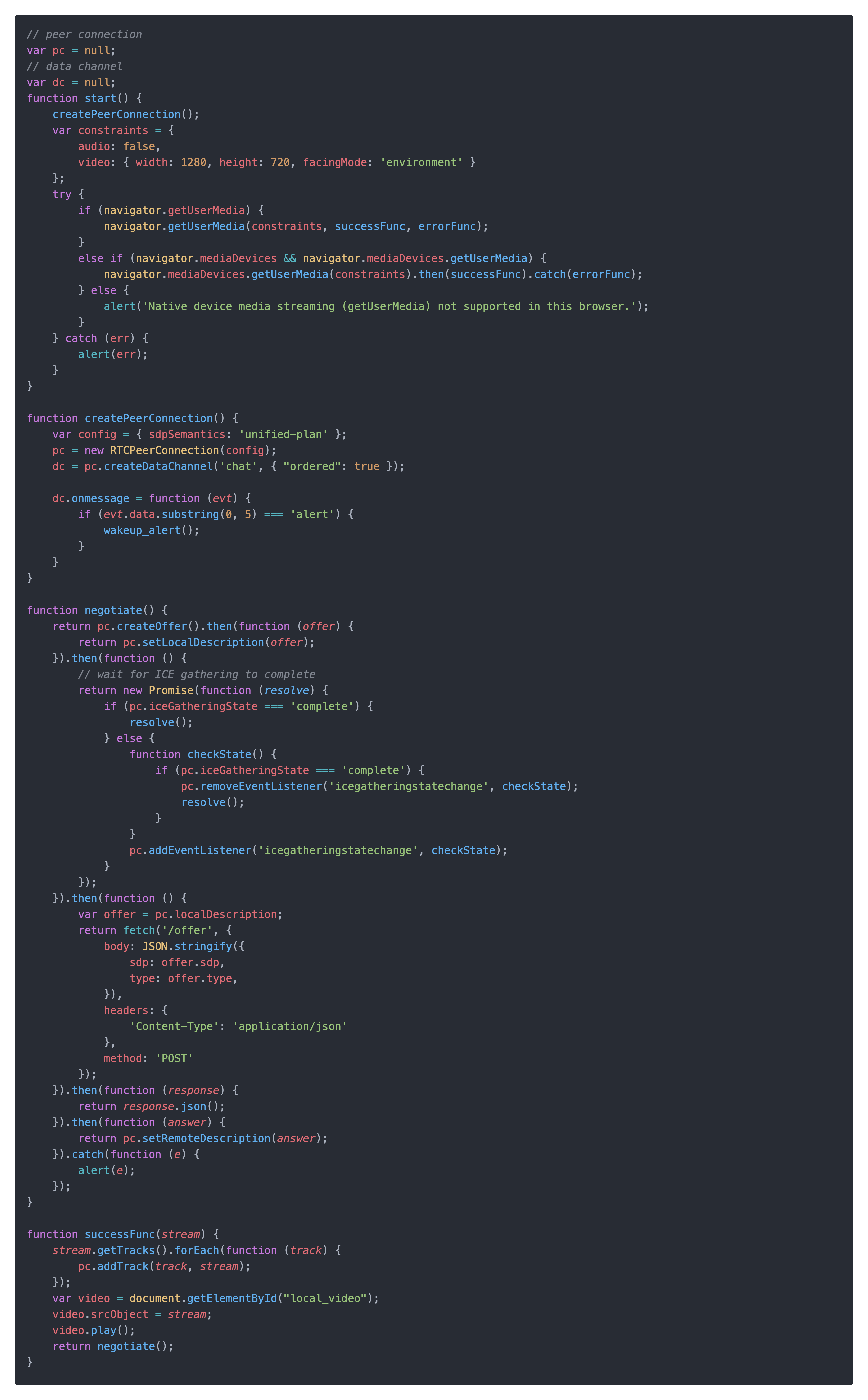
rtc.py实际处理webRTC建连的逻辑,通过创建PeerConnection并绑定相关回调函数,并给创建的PeerConnection绑定VideoTransformTrack,还可以绑定datachannel作为处理一般数据的通道,可以实现一般消息的接收和推送,后面的报警消息就是通过datachannel下发的。
 当连接建立后,视频流会通过PeerConnection上传到服务端,并会通过VideoTransformTrack,在recv方法中实现了视频流中图像检测和报警发出。
当连接建立后,视频流会通过PeerConnection上传到服务端,并会通过VideoTransformTrack,在recv方法中实现了视频流中图像检测和报警发出。
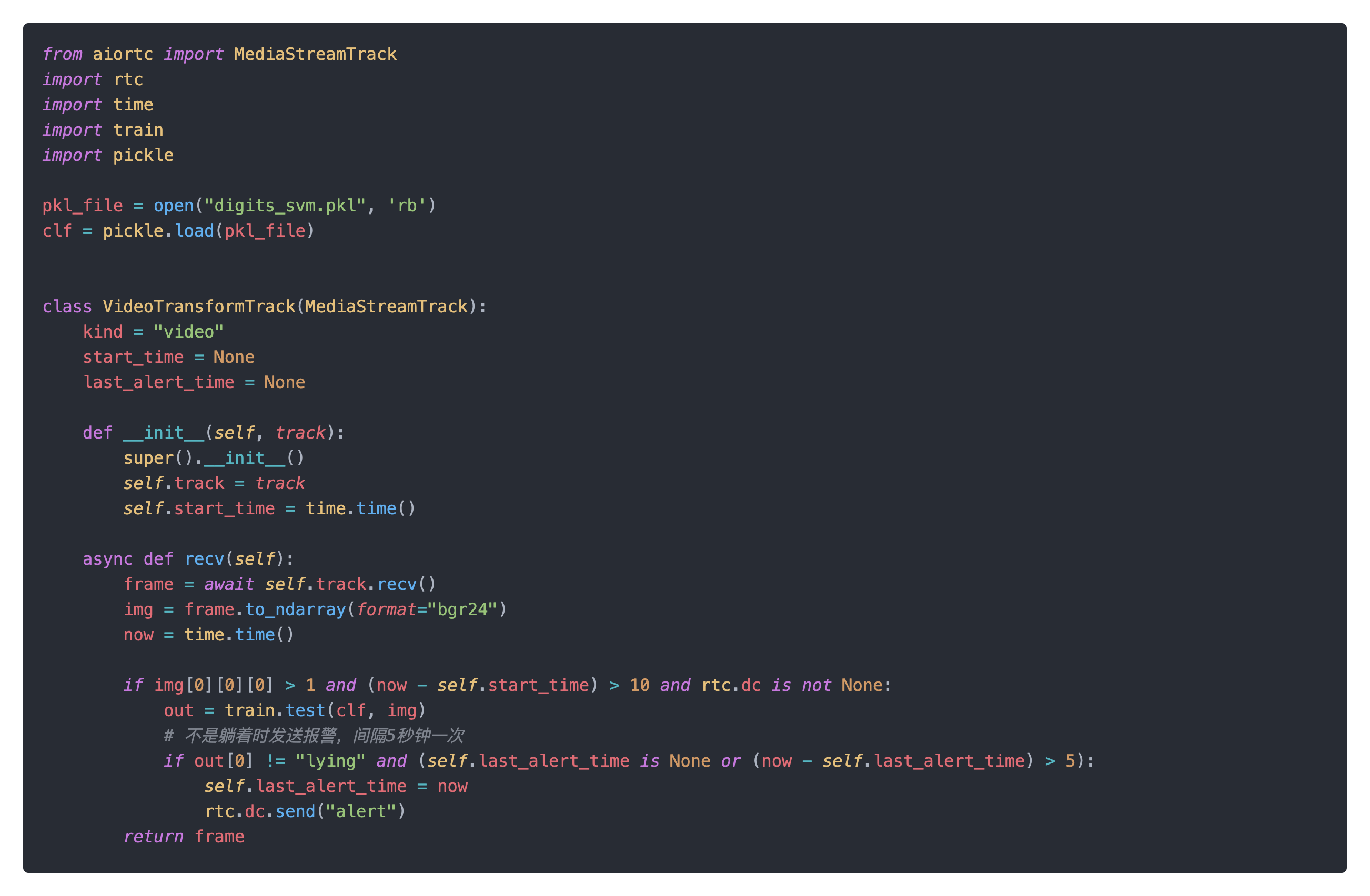 检测方法依赖于一个
检测方法依赖于一个digits_svm.pkl文件,这个文件是用sklearn的svm训练的模型。训练过程在train.py中,主要逻辑是加载trains文件夹下面的不同子文件夹中的图片,并以子文件夹名字作为对应图片的标签,通过svm进行模型训练及测试,最后保存生成的模型。
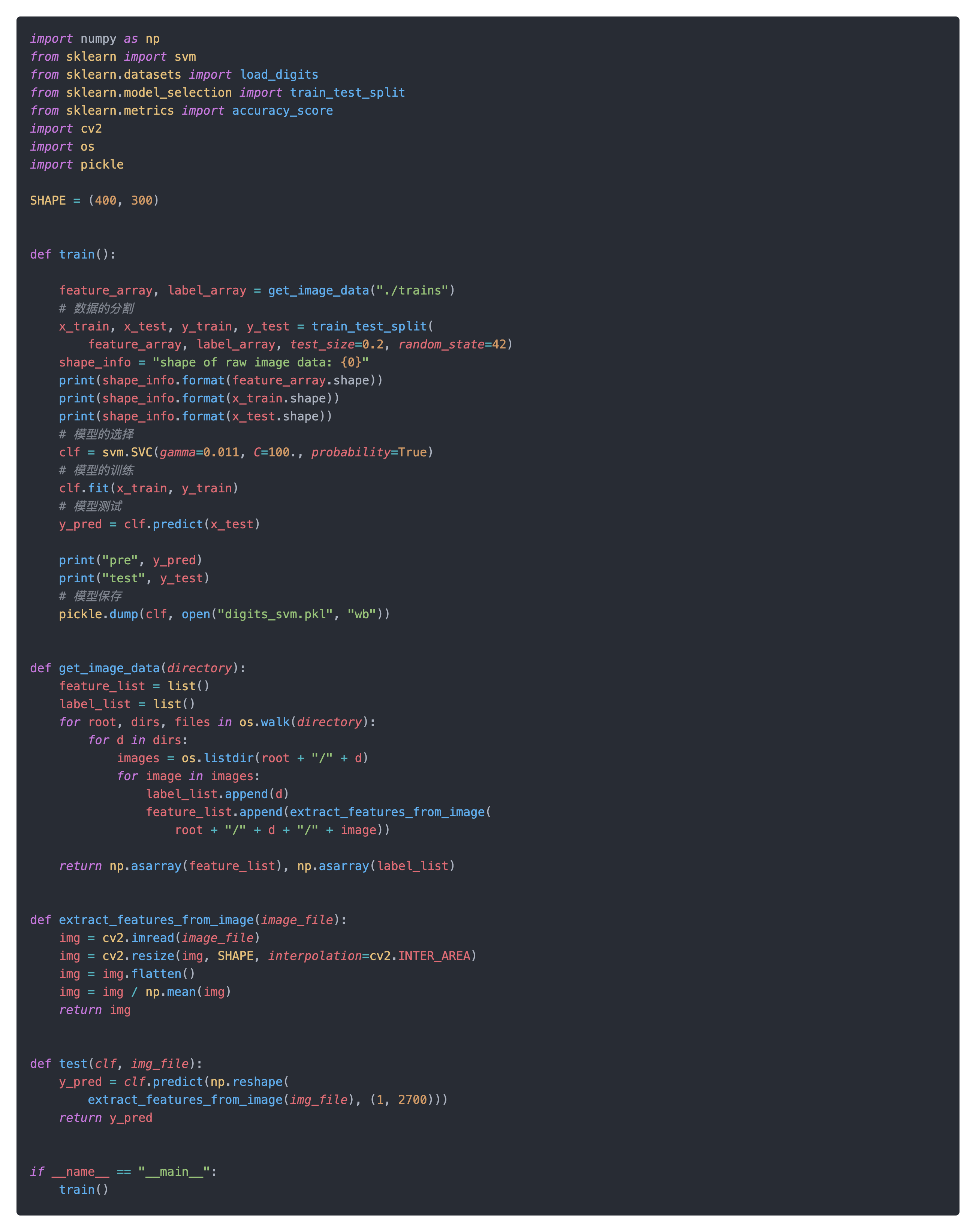
最后就是前端的逻辑,主要有一下webRTC是通过navigator.getUserMedia或navigator.mediaDevices.getUserMedia获取打开摄像头,可以设置是否要audio和video,且video也可以设置facingMode 来设置是否使用后置摄像头。在获取到摄像头的权限后,将对应的stream注册到创建PeerConnection中,并在网页上展示播放video。negotiate方法则主要是跟服务器发送和接收信令并建立连接。在createPeerConnection中为PeerConnection创建了一个DataChannel并监听了消息,如果服务端返回alert,则播放报警声音和展示报警动画。
效果检验和优化
一切就绪,找到了闲置了很久的一个平板,安装到了小麦子房间里。首先我录下了他睡觉的一段视频。通过区分睡觉的时候姿势和睡醒的爬或站立的姿势,截取了一系列图片,并将这些图片作为训练集和测试集来训练识别模型。 实验结果比较差强人意:
| 测试次数 | 成功次数 | 主要问题 |
| 10 | 3 | 模型误触发 |
模型由于训练数据比较少,比较难做到精确的识别,于是我开始转换思路,如果检测到视频里的物体运动则报警。运动物体检测的原理就是将动态的前景从静态的背景中分离出来。将当前画面与假设是静态背景进行比较发现有明显的变化的区域,就可以认为该区域出现移动的物体。opencv中提供了多种背景减除的算法,其中基于高斯混合模型(GMM)和基于贝叶斯模型的(GMG)最为常用。测试使用GMG检测方法,发现检查效果不错,最终video_transform_track.py代码如下。
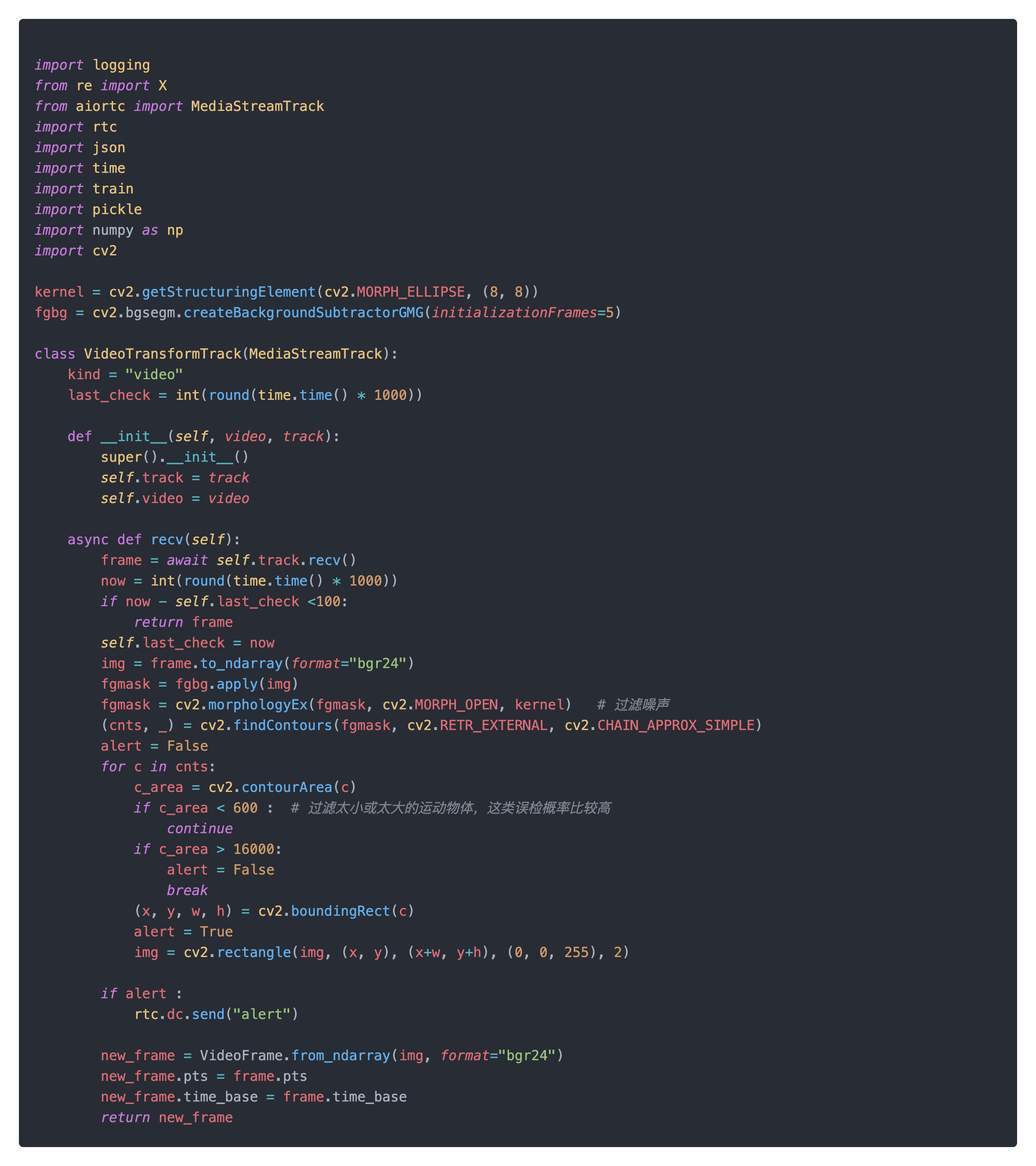 优化后,再次测试效果,结果如下
优化后,再次测试效果,结果如下
| 测试次数 | 成功次数 | 主要问题 |
| 10 | 10 | 无 |
写在最后
通过这次折腾,发现就上层应用来说,图像识别、行为识别等技术以及非常成熟且易用,普通人也能做出比较炫酷的应用。到今天小麦子头上的包也基本要散了,希望以后这个小家伙再也不会摔下床了。代码已经分享到了github上,有兴趣可以下载,欢迎⭐️star。
参考: