Discord是一款专为社群设计的免费网络实时通话软件与数字发行平台,主要针对游戏玩家、教育人士、朋友及商业人士,用户通过语音通话、视频通话、短信、媒体和文件进行私人聊天,或者在作为被称为Server的社区进行交流(服务器是一个可以通过邀请链接访问的永久聊天室和语音聊天频道的集合)。Discord运行在 Windows、 macOS、 Android、 iOS、 iPadOS、 Linux 和 web 浏览器上。截至2021年,该服务拥有超过3.5亿注册用户和超过1.5亿月活跃用户。
通过Discord Blog的两篇文章我们来了解学习下Discord面对海量消息是如何存储与Fanout。
消息存储
一开始,Discord采用MongoDB进行存储所有的消息,但是随着业务发展,消息量在短时间内迅速增加,此时不论在数据增长速度、整体消息体量以及可用性上都面临了一些挑战。
选择合适的数据库
技术人员先理解了当前的读写模式会面临哪些问题,总结如下:
- 读写方面:读非常随机,读写请求比例约1:1
- 语音较多的Discord Server几乎不发送消息。这个会造成消息数据时间分布较为广泛,当获取一部分消息数据时,可能面临多次磁盘随机查询以及磁盘缓存失效。
- 非公开Server的聊天消息量在10万到100万一年。几乎都是获取最近的消息。这里的问题点是:非公开群组聊天Server通常人数小于100人,他们请求数据频率也较低,所以也不太可能在磁盘缓存上
- 大型公开Discord Server发送非常多的消息。每天约上千的成员发送消息,每年将产生数百万的消息。成员几乎一直在发送消息和获取消息。他们的消息一般会在磁盘缓存中。
然后,确定了新的数据库的需求如下:
- 线性伸缩能力
- 自动故障转移能力
- 低/免维护
- 性能可靠(无需Redis和Memcached提高性能)
- 非二进制对象存储
- 开源
最后,Discord决定使用Cassandra作为其消息存储数据库,该数据库有较好的扩展能力,也容忍部分节点失败。其由Facebook进行开源,目前一些大型公司如Netflix和Apple也部署了上千节点的Cassandra集群。
简单来说Cassandra是一个KKV数据库。它有两个key,第一个key是分区key,用来决定哪一个节点存有这个数据以及在磁盘的哪个位置。分区里有非常多的数据行,数据行之间用第二个key作为索引,索引同时是分区的主键且是有序的。可以把一个分区看做一个有序的字典。
Discord将消息按时间分桶(bucket),使用(channel,bucket)作为Cassandra的分区Key,message id作为索引key, channel id和 message id都是通过雪花算法生成。获取最近消息的时候,由当前时间至channel生成的时间之间,获取足够的消息数据便返回。这样有个问题是:可能会跨越多个节点才能获取足够的消息,幸运的是活跃的channel不会出现这情况,而不活跃的channel几乎也不会查询。
性能
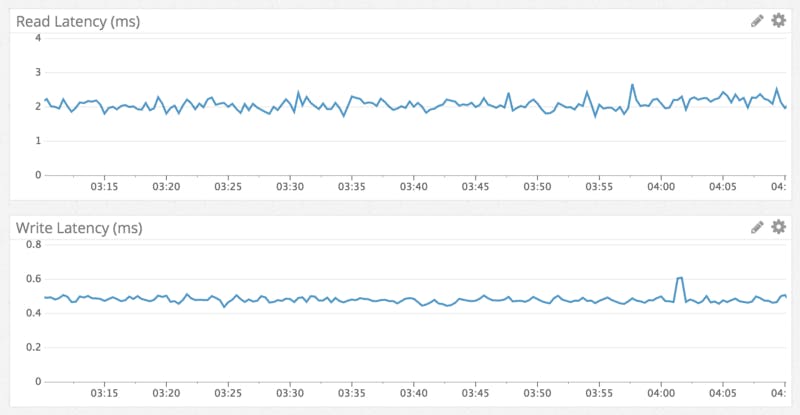
上线后Discord进行了性能监控,从下图可以看到,写的耗时大概是亚秒级,而读的耗时平均为5毫秒。而这也与Cassandra比较出名的写速度想吻合。
消息Fanout
Discord有很多丰富的特征,大多数可以归结为Pub/Sub,用户连接到一个WebSocket并启动一个Session进程(GenServer),然后会与远端的Guild进程通信(也是GenServer)。任何消息在工会发布时,它会被Fanout到与Guild相连的每一个会话中。
当用户上线时,会连接到一个Guild,此时Guild会发布一个上线消息到其他正连接到当前工会的连接会话,简单来说逻辑如下:
def handle_call({:publish, message}, _from, %{sessions: sessions}=state) do
Enum.each(sessions, &send(&1.pid, message))
{:reply, :ok, state}
end
上面的代码遍历当前的session并发送上线消息。当Discord最初建立一个小于25人的群组时,这是一个很好的办法。但是当Discord快速成长涌入大量用户,便出现了问题,例如名为/r/Overwatch的Discord Server,其拥有3万个同时在线的用户。在业务高峰时期,可以发现这些进程无法跟上它们的消息队列。
Discord的工程师对Guild进程内的热门路径进行了基准测试,然后很快发现一个明显的问题。在Erlang进程之间发送消息并不像预期的那么快,而且进程调度的成本也很明显,调用耗时可能在30到70us之间,这意味着在高峰时期,一个大公会发布一个事件的时间耗时在900ms到2100ms之间。Erlang的进程实际是单线程的,并行化工作使得唯一的方法是对它们进行拆分,然而这也是一个艰巨的任务。
Manifold
受到一篇关于提高节点建消息传递性能的博客文章启发,Manifold诞生了。Manifold分发发送消息的工作到远程PIDs节点(Erlang Process Identifier),这样的话发生的进程间调用次数便限制在了pids节点数量之内。Manifold首先根据Pid的远程节点对pid进行分组,然后发送到每一个节点上的Manifold.Partitioner(分区程序)。然后分区程序使用一致性hash处理PIDS并根据pids节点的核心数进行分组,并将他们发送给 actual processes。这保证了分区程序不会被过载,并且仍然提供了消息的线性化。
Manifold的带来的其他好处包括分散了cpu的负载,并且减少了节点间的网络传输